The Mini-App Predicament
Over the past year I've been asked by numerous people to document the experiences that Sean Treichler and I had in the process of porting a full production combustion simulation (S3D) to the Legion programming model. In particular, most of these people were interested in the problems we encountered when working with a full-scale application that we did not encounter with mini-apps. This blog post is an informal recounting of this class of problems and an argument for why mini-apps are valuable tools, but are insufficient for doing analysis of future HPC programming systems. In many cases the evidence presented here will be qualitative and anecdotal, but that makes it no less true, and conversations with many production application developers suggests that these experiences are pervasive throughout the HPC community.
Tl;dr: using lots of mini-apps for evaluation gives us the illusion of doing the right thing. In practice, mini-apps are useful vehicles for describing programmatic idioms and showcasing programming system features, but they are woefully incapable of conjuring any of the actual challenges that come up in real production applications. Read the rest if you want to find out why.
The Problem Scope
Before diving into any of the details, let's begin by defining the scope of the problem that we're trying to solve. We need to build high-performance programming systems capable of handling the challenges presented by future exascale applications. After discussions with many application developers, I've concluded that all future exascale application will be scientific simulations with one or more of the following properties:
- Dynamically Adaptive: relies on data structures that are dynamically changing throughout the execution of the program. This may come in the form of automatic refinement of irregular meshes, adaptive mesh refinement for regular grids, or mutable graph data structures, etc.
- Mixed Numerical Methods: explicit methods are easy to code, but implicit methods and direct solvers scale better to very large problem sizes. Implicit methods and direct solvers will dominate numerical methods, with possible explicit methods deployed at coarser scales.
- Multi-Physics: the phenomena being modeled are sufficiently complex that they require multiple different kinds of physics be modeled at different time scales and granularity within the same simulation, often with the various physics being simulated with different data structures.
- In-Situ Analysis and Visualization: the simulation will generate so much data that it will be intractable to write it all out to disk and post-process it, therefore data will need to be both analyzed and potentially visualized while it is still in memory.
- Uncertainty Quantification (UQ): a historically much-ignored area of computational science that tries to determine (often online) how sensitive computations are to various inputs and parameters. Usually this requires several iterations worth of data be kept around so the basic underlying computation can be played both backwards and forwards in time.
Of course the nightmare scenario is an application that needs to do all of these things. I know the question you are asking yourself, and the answer is yes, there are people that want to build exascale applications that have all of these characteristics (may god have mercy on their souls). I'm willing to wager actual money (come find me at a conference) that when all is said and done, these applications with all their peripherals including programming systems, libraries, domain specific languages, etc., will each be on the order of 10 million lines of code (on par with the Linux kernel). Clearly, building these kinds of applications requires deployment of good computer science practices, including leveraging the power of abstraction and building powerful programming systems that can be re-used across applications (on this I think most people agree). So now that we know we want to build these kinds of systems, how do we go about doing it?
The Bias-Variance Tradeoff
We have a definition for our problem, so let's couch it within a formal intellectual framework. I'll claim that the problem of designing and evaluating programming systems for future exascale HPC applications is a specific instance of the bias-variance tradeoff. As much as we wish it weren't so, we live in the real world with limited resources in terms of time, money, and people for evaluating programming systems, and it is impossible to evaluate our designs on all possible future exascale applications. Therefore, we have a choice before us: how do we train and evaluate our programming systems? Do we choose to minimize our bias (susceptibility to missing important features) or minimize our variance (susceptibility to over-fitting to specific applications). Ultimately, there is a spectrum here with two extremes:
- Using only small mini-apps (minimize bias)
- Using only a few large production codes (minimize variance)
The right answer is somewhere in between, but I will argue that it should skew much more towards minimizing variance than bias. Consider the risks of pursuing an approach at either extreme. If we use only a few production codes to design and evaluate our programming systems, we might end up with programming systems that only work for a few future production applications and don't have features for supporting other codes. Alternatively, using only mini-apps guarantees that our programming systems must work for many different types of codes, but the design will never be exposed to the class of problems I describe below. The end result would be that we have many programming systems that all overfit for many different small applications, and are wholly incapable of running any production codes!
In my opinion, skewing towards minimizing variance is the right tradeoff here because it will result in programming systems that will actually handle real production codes. The risk of additional bias can be mitigated by having different research programming systems be designed with different production codes in mind, ultimately ensuring that we have a working set of multiple programming systems that handle all important production codes. The alternative in which we can't run any production codes would be a colossal disaster and we must do everything in our power to avoid it. Having some working code is always better than having none.
Despite the obviousness of this conclusion, from everything that I have observed, we are currently taking the extreme path of only using mini-apps to do our evaluations of hardware and software systems. To the best of my knowledge, there are only two programming systems that have actually tackled production applications: Charm++ supports an implementation of the NAMD molecular dynamics code and Legion supports an implementation of S3D (see above). To further exacerbate matters, the hardware vendors responsible for delivering future exascale machines work almost exclusively with mini-apps with little-to-no engineering time designated for investigating full scale production codes. This places us in the precarious position of being purely at one extreme of the bias-variance tradeoff and leaves us exposed to the possibility that we completely overfit our hardware and software without ever tackling the truly important problems, such as the ones covered below.
Of course, the primary argument against working with full-scale production codes is that they are too large and unwieldy for actual engineers to work with and still do real research. Our work with porting S3D to Legion is the perfect counter-example to this claim. It required only two engineers working for 18 months (3 man-years) to port all of the main time-stepping loop of S3D into Legion. If we hadn't also been building Legion at the same time, it would likely only have taken us 3 months. Furthermore, by a combination of good design in Legion and use of good software engineering practices, we reduced the number of hand-written lines of code from 100K down to 10K (while also increasing the number of automatically generated lines to over 200K), resulting in much more maintainable code. There is no reason that the same process cannot be applied to other production codes with similar results.
The Problem of Simplicity
The first problem that we'll investigate is that of simplicity. Many people will argue that mini-apps are useful tools because of their simplicity and when it comes to illustrating concepts and describing how more complex applications work I couldn't agree more. However, when it comes to performance evaluations, this simplicity fails to reflect the vast number of scheduling degrees of freedom that real applications possess. I've noticed three primary consequences of this simplicity: a failure to explore sophisticated scheduling mechanisms, an over-emphasis on programming system overheads, and an inadequacy in capturing the nuance of tradeoffs. I want to explore all these effects in more detail, but I also want to make this description concrete, so let me first introduce a full-application and a mini-app that reasonably approximates some part of it.
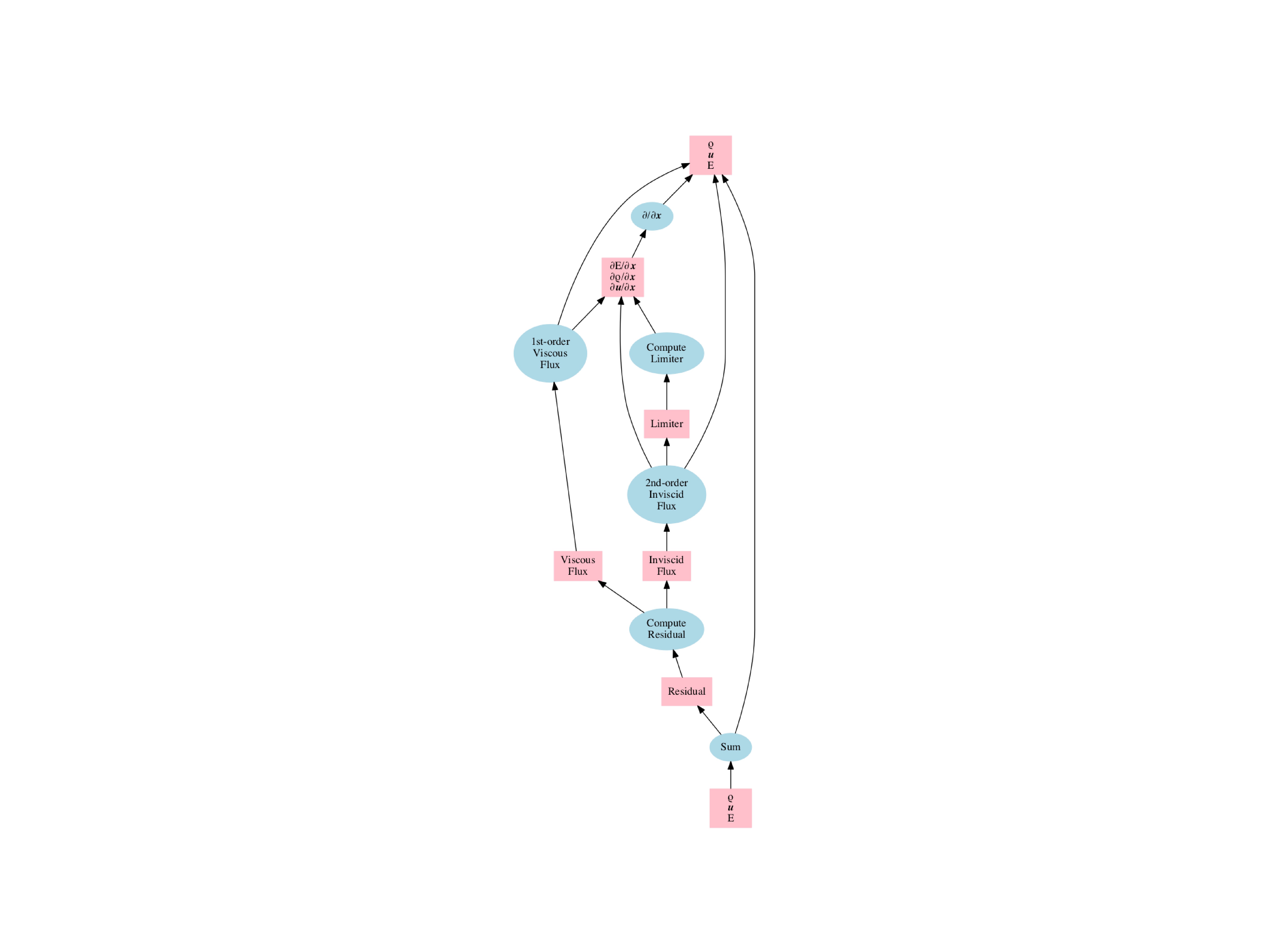
S3D is a large production combustion simulation that models all of the physical and chemical processes associated with the burning of hydro-carbon fuels. It uses an explicit six-stage, fourth-order Runge-Kutta (RK) numerical method to solve the Navier-Stokes equations as it iterates through time. It also is one example of a multi-physics code in that it also has separate models for all of the chemical reactions that it is modeling (although when most people talk about multi-physics, they mean physics on different meshes). Below is the dynamic dataflow graph generated at runtime for all the tasks in one time step of S3D on just a single node (a production run would contain up to 18000X the number of tasks per time step). Nodes represent computational tasks and edges represent data dependences between tasks on one or more fields. Unfortunately the edges are too small to be resolved by the lossy JPEG compression algorithm. You can download the original image here (1 MB download, may take up to 10 hours to render in full color with all 100K edges after transitive reduction depending on level of zoom) or you can download the original DOT file here (14 MB). If you could see the edges they would flow from left-to-right, with the vertical scale indicating the degree of task-level parallelism. Every rectangle is a separate task.

Alternatively, mini-aero is a small aerodynamics simulation that also uses a Runge-Kutta solver to simulate the Navier-Stokes equations. Below is the dynamic dataflow graph for one time step of mini-aero also on a single node (courtesy Sandia National Labs). In this case, edges from from bottom-to-top which means the width of the graph is the degree of task-level parallelism.
Clearly these dataflow graphs are have fundamentally different degrees of complexity. Perhaps the most striking thing to me as a human is that I have would have no trouble scheduling the mini-aero graph onto any machine by hand. I would determine the critical path, figure out how to minimize latency, and then assign the other computations and data movement to ensure not to exacerbate the latency of the critical path. The S3D graph on the other hand is way too complex for me to want to hand schedule anything. I don't know if it is latency limited or throughput limited (turns out it depends on which phase of the computation you look at). Determining this and where any critical paths lie would be very tedious. On a heterogeneous architecture, it's not immediately obvious to me which tasks need to go on CPUs versus GPUs. That's just the beginning of my questions... The complexity of the dataflow graph is now the primary feature that I use for determining if an application is a "real" application or a mini-app. If the graph is sufficiently complex that I would not want to schedule it by hand, then that is a "real" application. This is obviously a very subjective metric, but one that I have found to be a surprisingly good predictor of other peoples' classifications as well.
This brings me to the first major reason that simplicity is a detriment to evaluating programming systems for exascale: they don't actually require any sophisticated scheduling algorithms to ensure that they execute well on a target architecture. In many cases, they actually encourage scheduling be done by humans to ensure that applications perform well. Ultimately though, this will teach us very little about how well these programming system will be able to handle very large and sophisticated dataflow and task graphs for real production codes. The only way to really test these scheduling algorithms is by evaluating them on real applications which have the necessary complexity to truly stress scheduling algorithms.
The second major issue that this simplicity exacerbates is an over-emphasis on avoiding overhead. Today, many applications are limited by some form of latency due to the way they have been written. However, more often than not, exascale applications will have more than enough work to fill the machine and the problem will be maximizing throughput and not latency. The reason for this is that there are many peripheral computations going on in addition to the base computation (e.g. see the list above in-situ analysis, UQ, etc.). There will still be phases of computations that have critical paths, but they will be much less frequent. In a throughput limited application, there are many more degrees of scheduling freedom that have to be considered. Evaluating all these possibilities requires overhead, usually at runtime to map computations onto the target hardware well. When applied to mini-apps, where the correct scheduling decisions are trivial, the cost of this analysis shows up almost exclusively as pure overhead. However, in a full-scale production application with considerably more independent work, this analysis can easily be hidden and almost always pays for itself many times over.
The final and perhaps the most damning issue that the simplicity of mini-apps raises is an inadequacy at evaluating the need for tradeoff management. In real production codes, there are often at least two, and more commonly many, different ways that computations can be both expressed and mapped onto a particular machine. Expressing computations in a way that makes evaluating these tradeoffs and all their cross-products efficient is a challenging problem that requires the design of good abstractions that decouple specification from mapping, and efficient implementations capable of exploring large tradeoff spaces. However, with mini-apps it is very rarely the case that any tradeoffs are required. There is usually one correct answer for mapping and executing programs on a particular machine. By focusing solely on mini-apps, we risk not evaluating programming systems on one of their most fundamental aspects: the ability to manage and explore tradeoffs in the space of program expression and mapping. Failure to properly evaluate program systems on this design criteria will result in systems that are completely useless for large production codes where ambiguity and tradeoffs are ubiquitous.
In general, simplicity is a good thing when it comes to dealing with complex systems. However, when it causes us to improperly evaluate a system by not stressing a critical component such as the scheduling algorithm or its ability to evaluate complex tradeoffs, it is the perfect example of coming down in the wrong place in the bias-variance tradeoff by over-fitting to effects that will ultimately be noise in real applications.
The Problem of Rates
One of my friends from grad school likes to claim that the fundamental problem of graphics (and therefore in his mind all computing) is the problem of rates. In complex programs, different operations and events occur at different rates during execution. In graphics this takes the form of vertex, tessellation, and fragment shaders all having to run at different rates to ensure that compute load is well balanced, resources are properly utilized, and the graphics pipeline remains full. Not surprisingly, similar issues arise in production HPC applications due to several different causes which we'll explore below. However, these causes rarely, if ever, manifest in mini-apps.
The first cause of different rates in an HPC applications stems directly from the underlying physics of many applications. Most HPC applications today model multiple different physical phenomenon. The nature of physics is such that these different physical processes transpire over different time scales, often by several orders of magnitude. In S3D, chemical reactions occur much faster than the turbulent diffusion of chemical species. In some cases, more work has to be done for the chemistry computations to deal with stiff species to compensate for the difference in time scales. In even more sophisticated multi-physics codes some computations run once per time step while others run multiple times per time-step and yet others only need to run every few time steps. Under these circumstances dealing with the various different rates of computations and their resulting outputs is one instance of the problem of rates. In mini-apps in which there is almost universally a single physical process being modeled, the problem of rates due to multi-physics never arises.
Another cause of the problem of rates occurs from the differences between the primary simulation and in-situ analysis. Full production simulations need to employ in-situ analysis both to dynamically react to changing conditions within a simulation and to filter results to write out reasonable amounts of data to disk for post-processing. S3D contains examples of both kinds of in-situ analysis. S3D currently recomputes transport coefficients once per time step instead of once per RK stage. Even further analysis would allow the simulation to dynamically determine when transport coefficients need to be recomputed. The transport coefficient computations are hugely expensive and often require a different mapping of work to adjust to the increase load when they need to be performed. S3D also supports a dynamic in-situ analysis called Combustion Explosive Mode Analysis (CEMA) which samples a dynamic number of points per time step to determine when actual combustion is transpiring. Both of these analyses generate a dynamic amount of work often out of sync with the primary simulation loop which is executed six times per time step (due to the RK solver). Analyses which generate dynamic work at different rates from the primary simulation are another instance of the problem of rates. In mini-apps which primarily only model a simple physical simulation with no analysis, the problem of rates again never occurs.
The third cause of the problem of rates stems from the underlying hardware. In production simulations that exercise the whole machine dynamic hardware effects start to become more prevalent. This can range from dynamic voltage and frequency scaling (DVFS) within processors to complex cache effects due to dynamic working set sizes to dynamic routing in the interconnect system to react to contention from interfering communication traffic patterns. As the hardware reacts to these various loads, it can cause identical computations to run at different speeds in different parts of the machine. The result is yet another instantiation of the problem of rates. However, in mini-apps, where machines are often underloaded and computation is usually homogeneous and data parallel, the hardware rarely sees the competition for resources that full scale production applications create. As a result, mini-apps fail to create the conditions necessary to trigger the hardware mechanisms that cause yet another instance of the problem of rates.
The problem of different rates has many causes, but the solution in all cases has the same general form: a responsive and dynamic runtime system capable of monitoring these rates and reacting to them throughout execution to ensure load is balanced and system resources are utilized efficiently. However, in mini-apps where the problem of different rates never occurs, the cost of such a runtime that monitors system resources and computational load to effectively deal with the problem of different rates shows up as pure overhead. By only using mini-apps for evaluation we are incentivizing the reduction of overhead above the need for developing systems capable of dealing with the problem of rates. Low-overhead programming systems are important, but only to the extent that they are still capable of dealing with more fundamental problem of differing rates in all of its forms.
The Problem of Support
The final major issue with mini-apps is that they don't demand the co-design of a corresponding tool infrastructure as part of their development and deployment. In some ways this is an extension of the simplicity issues raised above, however, there are enough important distinctions that I've decided to raise it as a separate concern. While lines of code is a poor measure of complexity (Kolmogorov Complexity is a better metric, but harder to measure), most mini-apps are by their definition fairly short to avoid being complex. The trouble with only working with mini-apps is that they permit us to perpetuate the ludicrous human fallacy that we will be able to manually tune and debug all the code that we write (after all, we wrote it so we should understand it, right?). Look again at that dataflow graph from S3D above. What if I told you that there was a single missing dependence edge crucial to the correctness of the application; would you go looking for it by hand? Mini-apps don't force us to construct the necessary tools to help us with debugging and tuning. Consequently, we don't incorporate tool design as a first class design constraint for our programming systems and we don't observe the ramifications that our design decisions for programming models and programming systems have on tool construction.
The first kind of tools that often are only built to work with full scale applications are debugging tools. When implementing new programming systems two different classes of debugging tools have to be built: tools to help users, and tools to help developers. Assistance for end users is an absolute must, but tools to aid developers in debugging programming system implementations are equally important. This is especially true when developing runtime systems that operate over thousands of nodes and behave much more like a distributed system. As part of debugging Legion when running on thousands of nodes, Sean and I constructed three different tools, all of which had to be capable of scaling to long-running applications executing on a full machine. We constructed a tool called Legion Spy that proved essential in validating the correctness of Legion's dynamic extraction of implicit parallelism; we built a event graph analyzer capable of finding cycles in Realm event graphs containing billions of events; and we built a leak-detection analysis for finding memory leaks in both the Legion and Realm runtime systems. All of these tools required non-trivial amounts of engineering thought and effort. Only when working with a production grade application like S3D did it become apparent to us just how important these tools were to ensuring that our programming systems worked properly and scaled.
The other kind of tools that have to be built when constructing a new programming system are profiling tools. These are essential for figuring out where bottlenecks are occurring and when performance enhancements should be focused. Again, profiling tools need to built for both end users as well as for developers. As part of our work on S3D, we constructed an end-user profiler tool called Legion Prof, as well as several developer profiling tools capable of instrumenting our runtimes at various granularities: everything from active messages down to invocations and time spent in individual analysis functions. Just like the debugging tools, the profiling tools had to scale to the proportions of S3D running on thousands of nodes in order to find performance anomalies that only occurred at scale. We also invested considerable amounts of time in making sure that our profiling tools were designed and implemented to handle the workload of production applications. If we had solely focused on mini-apps, many of the apparent scalability problems associated with the amount of data generated and how to process it would never have arisen.
For both debugging and profiling tools it is crucial that these tools be capable of scaling to the complexity and size of production applications. As an example, when debugging our version of Legion S3D, we had to construct several tools for finding various correctness and performance bugs. These tools employed a mix of static and dynamic analysis, but they would often generate on the order of 10+ GB of data per node per run. For a run of 8K nodes, we therefore would need to process 80 TB of data. This required our tools themselves to be highly optimized and scalable programs (either embedded as part of our runtime, or as post-processing programs). In fact, it was only because Legion provides easy-to-analyze abstractions that we were able to limit the total volume of data generated and thereby ensure that our analyses were tractable. In several cases we actually modified our internal runtime data structures to make them more amenable to program analysis. This reflects a very subtle insight: our programming models and programming systems need to be designed to facilitate scalable program analyses if we are going to have any hope of constructing a usable tool infrastructure. This kind of coupling of tool design with programming model design is wholly absent from our design processes today because mini-apps don't demand tool support.
Our tool infrastructure for debugging and profiling must be co-designed with programming systems in order to be useful. However, only with sufficiently complex applications will we be able to observe the effects that our programming model design decisions have on the construction and scalability of support tools. The tools we build will need to be a mix of static and dynamic tools, but in all cases, they will have to be scalable: capable of dealing with complex codes, large machines, and the vast quantities of data that can be generated. If we don't consider the design of our tool chain as a first-class component of our programming systems, we may very well be constructing a world in which the full cognitive burden of debugging and tuning massively complex applications falls squarely on the shoulders of human programmers, and that is a recipe for disaster.
Why the Blackbird Succeeded
The SR-71 Blackbird has to be one of the coolest machines ever devised by man. During its tenure of service it set numerous sustained speed and altitude records surpassed even today only by actual space-faring craft. It was constructed with a singular purpose in mind: absolute speed. Consequently, no SR-71 was ever shot down during active service missions as it was simply able to accelerate away from any enemy missile. The cost of this safety was ease-of-use. The plane was notorious for being difficult to start, fly, and land. On the ground, the plane would constantly leak jet fuel as its manifold was intentionally designed to be loose fitting so that as surface temperatures climbed to 500 degrees Fahrenheit at mach 3.5, the manifold would naturally expand to create a perfect seal. In flight, the engines would occasionally unstart resulting in an extreme yaw that would toss crew members violently to one side of the plane. If anyone from the Pentagon had critiqued the plane on its ease of use or performance under basic flight maneuvers, like takeoff and landing, they would have concluded it was a hopelessly miserable beast of a plane and would have killed the program immediately. What everyone understood though was this: the SR-71 wasn't designed to fly like a normal plane; it was designed to fly at the very edge of the envelope where actual demons reside. As a result, the design of the SR-71 mandated tradeoffs that most normal aerospace engineers would never dream of contemplating. The Blackbird was successful though because it was designed and evaluated under the proper metrics; the result was quite simply the best spy plane ever built.
The trouble with mini-apps is that they don't represent the proper performance metrics for evaluating exascale-grade HPC programming models and software systems. As I've shown above, they don't create the same challenges that full-scale production applications do. If we continue evaluating programming systems exclusively using mini-apps then we will come down on the wrong side of the bias-variance tradeoff. The result will be a massive over-fitting of our designs to the wrong sets of features, ultimately dooming us to failure.
Mini-apps have their place: they are useful vehicles for conveying programmatic idioms and for showcasing how certain features of programming systems can be used to implement aspects of a larger application. When it comes to performance evaluations though, future exascale productions codes represent the equivalent of traveling at mach 3.5 and 80K feet. Only at this scale will the real challenges become manifest, and therefore it is the only domain under which future HPC programming systems can be properly evaluated.